
Gemini 2.5 Pro : Google tente de reprendre la couronne de l'IA – Pari réussi ?
Sur le papier, Gemini 2.5 Pro est le modèle d'IA le plus avancé de Google à ce jour. Il se vante d'un raisonnement de pointe, de performances exceptionnelles dans les tâches de mathématiques et de sciences, et d'une fenêtre de contexte qui peut atteindre un million de "tokens" (unités de texte), avec l'intention de doubler ce chiffre. Lancé en version expérimentale et actuellement gratuit, Gemini 2.5 Pro est un signal clair de Google au monde de l'IA : la course n'est pas finie, et Google est de retour dans la compétition.
Mais le produit est-il à la hauteur de la promesse ?
Alors que les commentaires des utilisateurs affluent et que les benchmarks (tests de performance) circulent, la conversation passe de l'enthousiasme du lancement à un examen plus approfondi, en particulier parmi les chefs d'entreprise, les développeurs et les investisseurs qui suivent la course à l'armement de l'IA. Voici une analyse de ce qui fait de Gemini 2.5 Pro un produit à surveiller, de ses points forts et des aspects qui méritent d'être abordés avec prudence.
1. Sous le capot : Quoi de neuf dans Gemini 2.5 Pro ?
Gemini 2.5 Pro est plus qu'une simple mise à jour de version. Il s'agit d'une amélioration architecturale substantielle présentée comme la pierre angulaire de la stratégie d'IA de Google en 2025.
- Capacités de raisonnement unifiées : Construit avec un moteur de raisonnement amélioré, Gemini 2.5 Pro utilise un apprentissage par renforcement affiné et des approches de type "chaîne de pensée". Les benchmarks montrent qu'il est en tête dans les tâches de raisonnement sans outils.
- Maîtrise multimodale : La prise en charge native du texte, de l'image, de l'audio et de la vidéo est toujours présente. Cela donne à Gemini un avantage dans la gestion d'ensembles de données complexes qui nécessitent une synthèse entre différents formats.
- Gestion du contexte à grande échelle : Avec une fenêtre de contexte d'un million de "tokens" – le double de ce que proposent généralement les concurrents – Gemini est optimisé pour les documents denses, les bases de code massives et les conversations prolongées. Une fenêtre de 2 millions de "tokens" est déjà en cours de test.
- Expertise en codage : Le modèle obtient de bons résultats aux tests SWE-bench et aux nouveaux benchmarks comme Aider Polyglot. Bien qu'il ne soit pas encore dominant dans les flux de travail de codage autonomes, il réduit l'écart.
- Options de déploiement : Actuellement disponible gratuitement via Google AI Studio et Gemini Advanced, avec l'intégration de Vertex AI à l'horizon. Les prix commerciaux complets sont attendus prochainement.
2. Données de référence : Où Gemini 2.5 Pro excelle
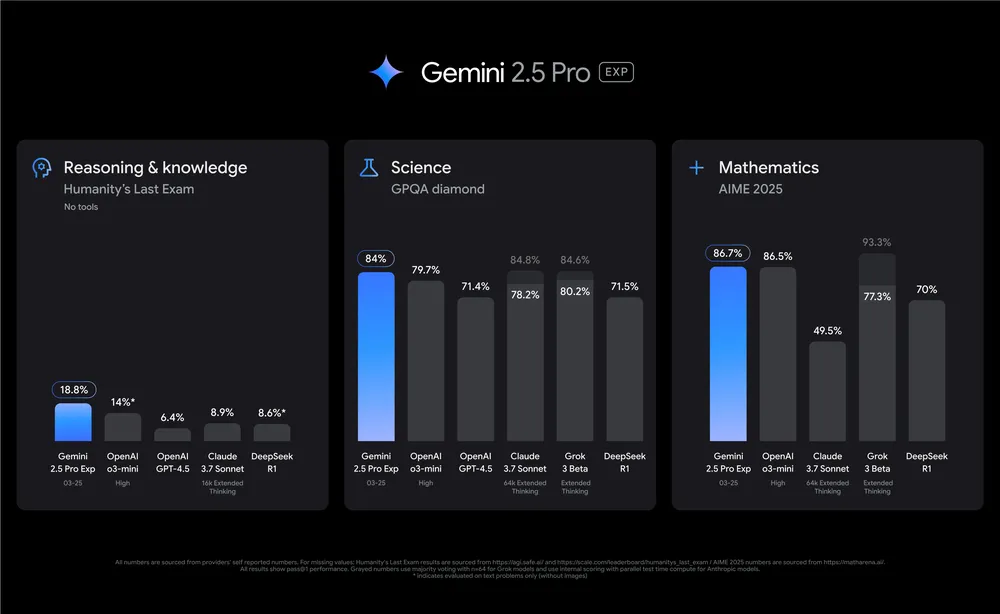
Raisonnement et connaissance
Dans des conditions "zero-shot" (sans exemples préalables) et sans outils, Gemini 2.5 a obtenu un score de 18,8 % dans les tâches de raisonnement complexes, soit le triple des performances de GPT-4.5 (6,4 %) et bien devant DeepSeek R1 (8,6 %). Cela en fait une option intéressante pour des domaines tels que l'analyse d'entreprise, l'analyse juridique et la modélisation de stratégies.
Mathématiques et sciences (AIME & GPQA)
Gemini 2.5 a dominé le benchmark AIME 2024 avec un score de 92,0 % et a affiché 86,7 % pour 2025. C'est bien au-dessus de Claude, Grok, et même du dernier o3-mini d'OpenAI. Pour les entreprises de la finance, de l'ingénierie ou du monde universitaire, cette compétence mathématique pourrait se traduire par des gains de productivité importants.
Compréhension multimodale
Le raisonnement visuel (81,7 %) et la compréhension d'images (69,4 %) suggèrent de solides performances multimodales. Notamment, Gemini 2.5 était le seul modèle avec un score rapporté sur la compréhension d'images, ce qui en fait un chef de file dans la compréhension inter-formats.
Rétention du contexte
Avec des scores de 91,5 % et 83,1 % aux benchmarks de contexte long, Gemini surpasse l'o3-mini d'OpenAI (36,3 % et 48,8 %). Cette capacité est essentielle pour les flux de travail juridiques, techniques et de recherche où la cohérence multi-documents est essentielle.
Capacité multilingue
Un score élevé (89,8 %) au benchmark Global MMLU Lite démontre la capacité de Gemini à traiter et à raisonner dans différentes langues, un atout essentiel dans les entreprises transfrontalières et les déploiements multinationaux.
3. Où Gemini 2.5 Pro est encore à la traîne
Malgré ses points forts, Gemini 2.5 Pro n'est pas sans lacunes, surtout par rapport à ses concurrents dans des tâches de niche.
Génération de code
Bien qu'il obtienne de bons résultats (70,4 % sur LiveCodeBench v5), il est à la traîne derrière l'o3-mini d'OpenAI (74,1 %). Pour les entreprises qui construisent des agents de code autonomes ou des pipelines d'outils internes, cela pourrait limiter l'efficacité à grande échelle.
Codage agentique
Gemini a obtenu un score de 63,8 % au benchmark SWE-bench, derrière les 70,3 % de Claude. Ceci est notable car la demande des entreprises pour "l'IA qui construit l'IA" continue de croître.
Exactitude des faits
Sur SimpleQA, Gemini a obtenu un score de 52,9 %, en deçà des 62,5 % de GPT-4.5. Dans les applications à forte confiance – finance, santé ou service client – cet écart de précision pourrait avoir un impact sur la fiabilité.
4. Sentiment réel : Les utilisateurs et les développeurs donnent leur avis
Sur des forums comme Reddit et X (anciennement Twitter), la réaction est mitigée.
- Éloges de la puissance : Les développeurs soulignent son raisonnement avancé et sa multimodalité native, tandis que d'autres célèbrent la date limite des connaissances de Google pour 2025, une première sur le marché.
- Critiques de l'accès et de la stabilité : Les utilisateurs signalent une disponibilité incohérente sur les différentes plateformes, et certains trouvent que les performances de Gemini 2.5 sont comparables à celles des versions antérieures comme Gemini 2.0 Flash. Un commentaire revient souvent : "On a plus l'impression d'un solide raffinement que d'une révolution."
- Préoccupations des développeurs : Les questions concernant la sortie structurée (par exemple, JSON), les agents de déploiement et les délais de lancement suggèrent un décalage entre les fonctionnalités annoncées et l'utilité pratique.
5. Paysage concurrentiel : Un tournant pour l'industrie
Le domaine de l'IA converge vers la spécialisation plutôt que vers l'échelle. Gemini 2.5 Pro, bien que puissant, entre sur un marché où la rentabilité et l'optimisation verticale deviennent les véritables champs de bataille.
- La série o3 d'OpenAI continue de mener dans le comportement agentique et les tâches de codage.
- Claude 3.7 Sonnet reste fort en matière de factuel et de raisonnement autonome.
- DeepSeek R1 émerge comme un outsider avec des performances impressionnantes à des coûts de calcul inférieurs, ce qui oblige les acteurs établis à repenser les prix et l'accessibilité.
Pour les investisseurs, cela signale un écosystème en maturation. À mesure que les modèles approchent de la saturation des capacités dans les benchmarks généraux, la différenciation proviendra des intégrations, de la stabilité du déploiement et du retour sur investissement par dollar d'inférence.
Gemini 2.5 Pro est un signal clair – mais pas la réponse finale
Gemini 2.5 Pro est le modèle d'IA le plus performant de Google à ce jour. Il établit un leadership dans le raisonnement, la compréhension du contexte long et les tâches multimodales. Mais il ne domine pas toutes les catégories – et les utilisateurs posent déjà des questions difficiles sur la disponibilité, l'exhaustivité et la valeur.
Pour les entreprises, Gemini 2.5 Pro offre une boîte à outils attrayante, en particulier dans les domaines à forte intensité de connaissances. Pour les investisseurs, il reflète un pivot plus large de l'industrie : de la construction de modèles plus grands à la construction de modèles meilleurs.
Points clés à retenir :
- Gemini 2.5 Pro est un bond en avant technique, en particulier dans le raisonnement et les tâches riches en contexte.
- Les benchmarks confirment le regain de compétitivité de Google, mais mettent également en évidence des lacunes essentielles en matière d'exactitude des faits et de flux de travail agentiques.
- L'adoption réelle dépendra de la rapidité de la livraison, de la clarté des prix et de l'établissement d'une relation de confiance avec les développeurs.