
Les modèles QAT Gemma 3 de Google démocratisent l'IA avancée pour le matériel grand public
Google a lancé des versions quantifiées de son puissant modèle de langage Gemma 3 27B QAT, permettant à l'IA de pointe de fonctionner sur du matériel grand public. Les nouvelles variantes de formation tenant compte de la quantification (Quantization-Aware Training - QAT) réduisent considérablement les besoins en mémoire tout en maintenant des performances comparables à celles de leurs homologues en pleine précision, marquant ainsi un tournant dans l'intégration de capacités d'IA avancées dans les appareils personnels.

La puissance d'un supercalculateur sur les GPU grand public
Dans un petit appartement à Brooklyn, Maya Chen, développeuse de logiciels, exécute une génération d'images IA complexe et une analyse de texte qui nécessiteraient généralement des services cloud coûteux ou du matériel spécialisé. Son secret ? Une carte graphique NVIDIA RTX 3090 vieille de deux ans exécutant le nouveau modèle Gemma 3 27B QAT de Google.
"C'est révolutionnaire", explique Chen en faisant la démonstration du système. "J'exécute ce qui équivaut à une IA de niveau supercalculateur sur du matériel que je possédais déjà. Avant cette version, ce n'était tout simplement pas possible."
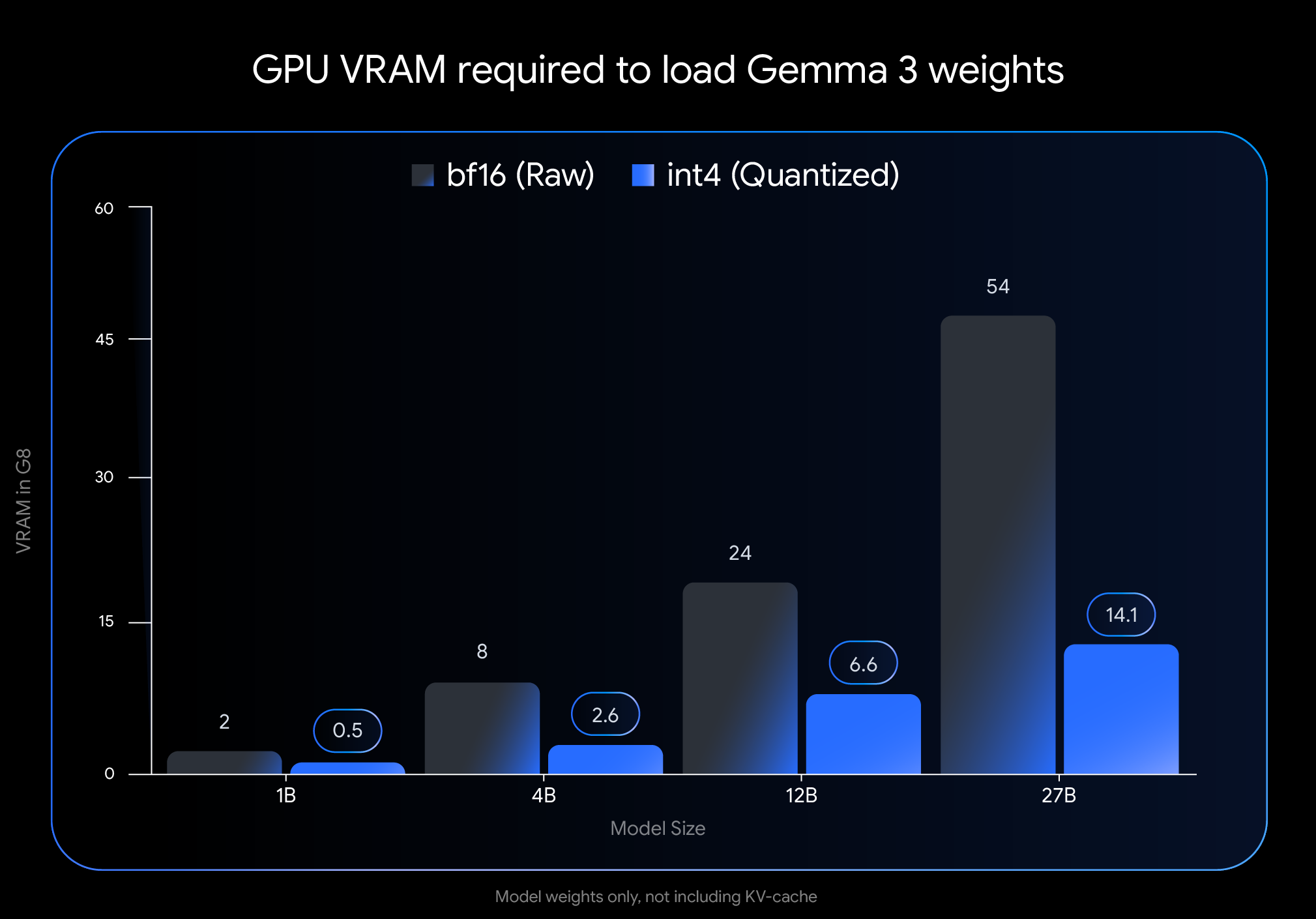
L'expérience de Chen reflète la promesse de l'annonce de Google du 18 avril : démocratiser l'accès à l'IA de pointe en la faisant fonctionner efficacement sur du matériel grand public largement disponible. Le lancement de Gemma 3 le mois dernier l'a établi comme un modèle ouvert de premier plan, mais ses besoins élevés en mémoire limitaient le déploiement à du matériel coûteux et spécialisé. Les nouvelles variantes QAT changent complètement cette dynamique.
Percée technique dans la compression de modèles
Les modèles quantifiés représentent une percée technique dans la compression de modèles d'IA. Les approches traditionnelles de réduction de la taille des modèles entraînaient souvent une dégradation significative des performances, mais la mise en œuvre de la formation tenant compte de la quantification par Google introduit une approche novatrice.
Contrairement aux méthodes de quantification post-formation conventionnelles, QAT intègre le processus de compression pendant la phase de formation elle-même. En simulant des opérations de faible précision pendant la formation, les modèles s'adaptent pour fonctionner de manière optimale même lorsqu'ils sont finalement déployés avec une précision numérique réduite.
"Ce qui rend cette approche particulièrement efficace, c'est la méthodologie de formation", note un chercheur en apprentissage automatique qui a analysé les modèles. "En appliquant QAT sur environ 5 000 étapes et en utilisant les probabilités de points de contrôle non quantifiés comme cibles, ils ont réduit la baisse de perplexité de 54 % par rapport aux techniques de quantification standard."
L'impact sur les besoins en mémoire est spectaculaire. L'empreinte VRAM du modèle Gemma 3 27B passe de 54 Go à seulement 14,1 Go, soit une réduction de près de 74 %. De même, la variante 12B passe de 24 Go à 6,6 Go, la 4B de 8 Go à 2,6 Go et la 1B de 2 Go à seulement 0,5 Go.
Ces réductions rendent les modèles auparavant inaccessibles viables sur le matériel grand public. Le modèle phare 27B fonctionne désormais confortablement sur les GPU de bureau comme le NVIDIA RTX 3090, tandis que la variante 12B peut fonctionner efficacement sur les GPU d'ordinateurs portables tels que le NVIDIA RTX 4060.
Les performances dans le monde réel valident l'approche
Ce qui distingue la mise en œuvre de Google des tentatives précédentes de quantification de modèles, c'est l'impact minimal sur les performances. Des benchmarks indépendants suggèrent que les modèles QAT conservent une précision de 1 % par rapport à leurs homologues en pleine précision.
Dans les classements Chatbot Arena Elo, une mesure largement respectée des performances des modèles d'IA basée sur les préférences humaines, les modèles Gemma 3 obtiennent des scores impressionnants. La variante 27B atteint un score Elo de 1338, la plaçant parmi les meilleurs modèles ouverts malgré le fait qu'elle nécessite beaucoup moins de puissance de calcul que ses concurrents.
Les commentaires de la communauté corroborent ces mesures officielles. Les utilisateurs des forums de développeurs rapportent que les modèles QAT "semblent plus intelligents" que les autres variantes quantifiées. Dans des comparaisons directes utilisant la métrique GPQA diamond difficile, le Gemma 3 27B QAT a surpassé les autres modèles quantifiés tout en utilisant moins de mémoire.
"Nous avons constaté des temps de réponse quasi instantanés dans les applications en temps réel", déclare un développeur qui a intégré le modèle dans une application mobile. "Cela rend Gemma 3 pratique pour les déploiements périphériques où la latence et les contraintes de ressources sont des facteurs critiques."
Les capacités multimodales élargissent les cas d'utilisation
Au-delà des performances brutes, Gemma 3 intègre des innovations architecturales qui étendent ses capacités au-delà du traitement de texte. L'intégration d'un encodeur de vision permet aux modèles de traiter des images en même temps que du texte, bien que certains experts notent des limites dans la profondeur de la compréhension visuelle par rapport aux systèmes spécialisés plus importants.
Une autre avancée significative est la prise en charge des fenêtres de contexte étendues : jusqu'à 128 000 jetons pour la plupart des variantes et 32 000 pour le modèle 1B. Cela permet à l'IA de traiter des documents et des conversations beaucoup plus longs que la plupart des modèles accessibles aux consommateurs.
"La mise en œuvre d'un mécanisme d'attention locale/globale entrelacée réduit considérablement l'empreinte mémoire requise pour l'inférence de contexte long", explique un ingénieur en apprentissage automatique connaissant l'architecture. "Cela permet de traiter des documents volumineux sur des GPU grand public sans sacrifier la compréhension."
La prise en charge de l'écosystème facilite l'adoption
Google a privilégié la facilité d'intégration, en publiant les modèles dans des formats compatibles avec les outils de développement populaires. Les modèles QAT non quantifiés int4 et Q4_0 officiels sont disponibles sur Hugging Face et Kaggle, avec une prise en charge native des outils tels que Ollama, LM Studio, MLX pour Apple Silicon, Gemma.cpp et llama.cpp.
Cette prise en charge de l'écosystème a accéléré l'adoption parmi les développeurs et les chercheurs indépendants. Les forums de discussion regorgent de rapports de déploiements réussis sur diverses configurations matérielles et cas d'utilisation.
"La large prise en charge des outils et le processus de configuration facile ont été cruciaux", déclare un développeur qui a intégré le modèle dans une application éducative. "Nous avons pu déployer localement en quelques heures, éliminant ainsi les coûts du cloud tout en maintenant la qualité de la réponse."
Limites et orientations futures
Malgré les avancées, les experts identifient plusieurs domaines dans lesquels les modèles Gemma 3 sont encore confrontés à des limites. Bien qu'ils puissent traiter des contextes longs, certains utilisateurs notent que la capacité de raisonner en profondeur à travers des entrées très volumineuses reste difficile, en particulier pour les tâches analytiques complexes.
Le composant de vision, bien qu'efficace, n'est pas aussi sophistiqué que dans certains modèles multimodaux plus grands et formés conjointement. Cela peut affecter les performances dans les tâches nécessitant une compréhension visuelle nuancée.
De plus, certains chercheurs en apprentissage automatique soulignent qu'une grande partie des performances de Gemma 3 provient d'une distillation sophistiquée des connaissances à partir de modèles enseignants plus puissants, probablement de la famille Gemini propriétaire de Google. Cette dépendance, ainsi qu'une certaine opacité dans la méthodologie post-formation, limitent la reproductibilité complète par la communauté de recherche en IA au sens large.
Démocratiser le développement de l'IA
La publication représente une étape importante pour rendre les capacités d'IA avancées accessibles à un plus large éventail de développeurs, de chercheurs et de passionnés. En permettant le déploiement local sur du matériel courant, les modèles Gemma 3 QAT réduisent les barrières à l'entrée en termes de coût et d'exigences techniques.
"Il s'agit de bien plus que de simples capacités techniques", réfléchit Chen, le développeur de Brooklyn. "Il s'agit de savoir qui peut innover avec ces technologies. Lorsque l'IA puissante fonctionne localement sur du matériel grand public, cela ouvre des portes aux individus et aux petites équipes qui n'auraient pas les moyens de se payer une infrastructure spécialisée."
Alors que l'IA influence de plus en plus divers aspects du développement technologique, la capacité d'exécuter des modèles sophistiqués localement pourrait s'avérer transformatrice pour l'innovation au-delà des grandes entreprises technologiques. L'approche de Google avec Gemma 3 QAT suggère un avenir où l'IA de pointe devient un outil démocratisé plutôt qu'une ressource centralisée.
La concrétisation de cette vision dépend de la manière dont la technologie évolue et de la manière dont la communauté des développeurs au sens large adopte ces capacités. Pour l'instant, cependant, l'écart entre la recherche de pointe en IA et le déploiement pratique s'est considérablement réduit, un développement qui pourrait avoir des implications considérables pour l'avenir de l'accessibilité à l'IA.