
Alibaba Défie Google & OpenAI : Découvrez Qwen2.5-Omni, l'IA Open Source Qui Voit, Entend et Parle
La course à l'IA vient de s'enrichir d'un nouvel acteur majeur. Alors que Gemini de Google et OpenAI nous éblouissent avec leurs capacités multimodales (comprendre les images, les vidéos et l'audio en plus du texte), l'équipe Qwen d'Alibaba a discrètement lancé une possible bombe : Qwen2.5-Omni. Ce n'est pas juste un autre grand modèle de langage ; c'est une IA multimodale "omnidirectionnelle" conçue dès le départ pour percevoir le monde comme nous le faisons. Elle traite le texte, les images, l'audio et la vidéo, et répond non seulement par du texte, mais aussi par une parole synthétisée en temps réel.
Le plus révolutionnaire ? Alibaba a rendu open source la version à 7 milliards de paramètres, Qwen2.5-Omni-7B, sous licence Apache 2.0. Cette décision met potentiellement des outils d'IA multimodale sophistiqués directement entre les mains des développeurs et des entreprises du monde entier, gratuitement pour une utilisation commerciale. C'est un pari audacieux, qui défie les jardins clos de ses principaux concurrents.
Que se Cache-t-il Sous le Capot ? L'Architecture "Thinker-Talker"
Alibaba n'a pas simplement ajouté des sens à un LLM existant. Ils ont introduit une nouvelle architecture "Thinker-Talker" (Penseur-Parleur).
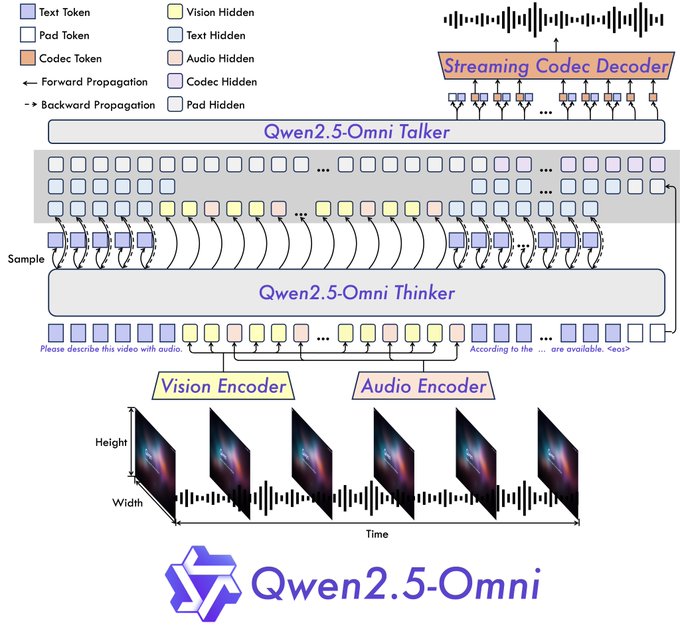
- Le Penseur (Thinker) : Ce composant agit comme le cerveau. Il reçoit les diverses entrées (texte, visuels, sons) et les traite pour comprendre le contexte et générer des représentations sémantiques de haut niveau, ainsi que la réponse textuelle principale. Il utilise des encodeurs dédiés pour l'audio et la vision afin d'extraire les caractéristiques pertinentes.
- Le Parleur (Talker) : Fonctionnant comme la bouche et les cordes vocales, le Parleur reçoit les informations sémantiques et le texte du Penseur en temps réel. Il synthétise ensuite ces éléments en jetons audio discrets, générant un flux de parole naturelle en même temps que le texte écrit.
Cette conception de bout en bout est essentielle pour permettre des expériences interactives en temps réel. L'architecture prend en charge les entrées fragmentées et les sorties immédiates, visant des conversations qui ressemblent plus à un appel vidéo qu'à une conversation par messages.
De plus, Qwen2.5-Omni intègre une nouvelle technique d'intégration de position appelée TMRoPE (Time-aligned Multimodal RoPE). Cela répond spécifiquement à un problème délicat : synchroniser avec précision les images vidéo avec leurs segments audio correspondants le long d'une chronologie partagée. Bien faire cela est essentiel pour comprendre correctement les actions et la parole dans le contenu vidéo.
Allégations de Performance vs. Tests en Conditions Réelles : Sens Impressionnants, Intelligence Discutable ?
Alibaba affirme que Qwen2.5-Omni obtient des résultats de pointe sur OmniBench, un benchmark conçu pour les tâches multimodales intégrées. Ils rapportent également qu'il surpasse les modèles de taille similaire, y compris les concurrents à code source fermé comme Gemini 1.5 Pro de Google sur certaines tâches, et même les modèles unimodaux spécialisés de leur propre gamme (comme Qwen2.5-VL-7B pour la vision et Qwen2-Audio).
Les démos officielles et les premiers tests utilisateurs brossent un tableau fascinant, quoique mitigé :
- Les Avantages – Prouesses Multimodales :
- Vision : Il a correctement identifié un "comportement suspect" dans une image de flux de sécurité simulée, fournissant une classification et un raisonnement corrects.
- Vidéo : À partir d'une vidéo de danse, il a fourni une description détaillée de la tenue du danseur, de ses mouvements et du décor.
- Audio : Il a correctement résumé les étapes de la préparation du porc braisé rouge à partir d'une recette audio téléchargée.
- Interaction : La sortie simultanée de texte et de voix naturelle (gérant bien le mélange anglais/chinois) est rapide et fluide, créant une sensation de conversation authentique. Les démos présentent des appels vidéo où l'IA décrit l'environnement, agit comme un assistant de recette guidé par la voix, critique des brouillons de chansons, analyse des croquis et même donne des cours particuliers de mathématiques étape par étape à partir d'une photo.
- Les Inconvénients – Erreurs de Raisonnement & Obstacles Pratiques :
- Échecs de Logique de Base : Malgré son traitement sensoriel avancé, le modèle de démonstration 7B a trébuché sur des tâches de raisonnement simples. À la question "Lequel est le plus grand, 6,9 ou 6,11 ?", il a déclaré à tort que 6,9 était plus petit. À la question de savoir combien de "r" il y a dans "strawberry" (fraise en anglais), il a répondu deux (il y en a trois). Cela suggère un écart potentiel entre la capacité de perception et le raisonnement cognitif, du moins dans cette version accessible.
- Intensité des Ressources : Certains utilisateurs tentant d'exécuter le modèle localement ont signalé des besoins importants en VRAM, un cas signalant une erreur de mémoire insuffisante sur une configuration VRAM de 100 Go pour une vidéo de 21 secondes. D'autres ont noté des erreurs avec des images plus grandes et des temps de génération lents (minutes par réponse), ce qui laisse entendre qu'un déploiement efficace pourrait nécessiter une optimisation ou des configurations matérielles spécifiques.
- Langue & Personnalisation : Bien que la sortie vocale en anglais et en chinois soit forte, les utilisateurs ont noté des limitations avec d'autres langues comme l'espagnol et le français. La sortie vocale reflète actuellement le texte ; davantage d'options de personnalisation seraient bénéfiques pour des applications spécifiques. L'accessibilité pour les utilisateurs non experts a également été signalée comme nécessitant des améliorations.
Le Pari de l'Open Source : Démocratiser l'IA Multimodale ?
La décision d'Alibaba de rendre open source Qwen2.5-Omni-7B sous la licence Apache 2.0, qui autorise l'utilisation commerciale, est peut-être l'aspect stratégiquement le plus important de cette publication.
- Réduire les Barrières : Cela permet aux startups, aux chercheurs et même aux entreprises établies d'expérimenter et de déployer une IA multimodale avancée sans les coûts API exorbitants ou les frais de licence associés aux modèles fermés. Cela pourrait stimuler l'innovation dans des domaines tels que :
- Outils d'accessibilité : Une IA capable de décrire le monde pour les malvoyants.
- Éducation : Des tuteurs interactifs capables de voir le travail d'un élève et d'entendre ses questions.
- Assistance Créative : Des outils qui critiquent l'art visuel, la musique ou l'écriture en fonction de multiples entrées.
- Appareils Intelligents : Permettre une interaction plus naturelle avec les appareils portables (comme le concept de lunettes intelligentes mentionné par les utilisateurs) ou les assistants à domicile.
- Pression Concurrentielle : Cette décision défie directement les modèles commerciaux d'OpenAI et de Google, les forçant potentiellement à reconsidérer leurs prix ou à proposer des versions plus accessibles de leurs propres modèles de pointe. Le commentaire de l'utilisateur qualifiant cela de "véritable OpenAI" reflète un segment de la communauté des développeurs avide d'outils puissants et ouverts.
- Construction d'un Écosystème : Pour Alibaba, cela pourrait être une stratégie visant à construire un écosystème de développeurs autour de ses modèles Qwen, favorisant une adoption plus large et stimulant potentiellement l'utilisation de sa plateforme cloud où le modèle est également hébergé.
Conclusion : Un Pas Puissant, Mais le Voyage Continue
Qwen2.5-Omni est indéniablement une avancée significative dans l'IA multimodale, particulièrement impressionnante pour son intégration transparente de diverses entrées et sa sortie texte-parole en temps réel au sein d'une nouvelle architecture. La mise en open source du modèle 7B est une décision majeure qui pourrait avoir un impact significatif sur le paysage de l'IA, donnant du pouvoir aux développeurs et aux entreprises du monde entier.
Cependant, les tests initiaux mettent en évidence une réalité cruciale : une perception sensorielle avancée ne se traduit pas automatiquement par un raisonnement parfait ou un déploiement sans effort. Les erreurs logiques observées et les exigences en ressources signalées montrent qu'il reste encore des obstacles à surmonter.
Pour les entreprises et les investisseurs, Qwen2.5-Omni représente à la fois une opportunité et un point d'observation. L'opportunité réside dans l'exploitation de cet outil puissant et accessible pour l'innovation. Le point d'observation consiste à observer comment le modèle mûrit, comment la communauté aborde ses limitations et comment les concurrents réagissent à ce défi open source. Alibaba a joué une carte forte ; les prochains mouvements dans le jeu à enjeux élevés de l'IA sont attendus avec impatience.
Ressources :
- Démo : https://huggingface.co/spaces/Qwen/Qwen2.5-Omni-7B-Demo
- Expérience de Chat Qwen : https://chat.qwen.ai/
- GitHub : https://github.com/QwenLM/Qwen2.5-Omni
- Modèle Hugging Face : https://huggingface.co/Qwen/Qwen2.5-Omni-7B
- Rapport Technique : https://github.com/QwenLM/Qwen2.5-Omni/blob/main/assets/Qwen2.5_Omni.pdf
- Article de Blog : https://qwenlm.github.io/blog/qwen2.5-omni/